
[DB] NoSql 과 Redis
NoSql 과 Redis
RDBMS
- 데이터를 관계로 표현한다. (열과 행이 있는 테이블로 표현)
- 테이블 형식의 데이터를 조작할 수 있는 관계 연산자 제공.
- 트랜잭션 시 강력한 ACID 제공.
Atomicity : All or Noting. 모두 반영되거나 전혀 반영되지 않거나.
Consistency : 트랜잭션이 일어난 이후의 데이터베이스는 데이터베이스의 제약 이나 규칙(무결성 같은)을 만족해야 한다.
Isolation : 각각의 트랜잭션은 서로 간섭 없이 독립적으로 이루어져야 한다. (마이너스 통장 예시)
Durability : 트랜잭션이 성공적으로 완료 되었을 경우, 결과는 영구적으로 반영되어야 한다.
NoSql
단순히 기존 관계형 DBMS가 갖고 있는 특성뿐만 아니라, 다른 특성들을 부가적으로 지원하는 DB.
왜 각광 받게 되었나?
관계형 데이터 또는 정형데이터가 아닌 데이터, 즉 비정형데이터라는 것을 보다 쉽게 담아서 저장하고 처리할 수 있는 구조를 가진 데이터 베이스들이 관심을 받게 되었고, 해당 기술이 점점 더 발전하게 되면서, NoSQL 데이터베이스가 각광을 받게 되었다.
특징
- 관계형 모델을 사용하지 않으며 테이블간의 조인 기능 없음
- 직접 프로그래밍을 하는 등의 비SQL 인터페이스를 통한 데이터 액세스
- 대부분 여러 대의 데이터베이스 서버를 묶어서(클러스터링) 하나의 데이터베이스를 구성 (수평적 확장)
- 관계형 데이터베이스에서는 지원하는 Data처리 완결성(Transaction ACID 지원) 미보장
- 데이터의 스키마와 속성들을 다양하게 수용 및 동적 정의 (Schema-less)
- 데이터베이스의 중단 없는 서비스와 자동 복구 기능지원
- 확장성, 가용성, 높은 성능
NoSQL은 초고용량 데이터 처리 등 성능에 특화된 목적을 위해, 비관계형 데이터 저장소에, 비구조적인 데이터를 저장하기 위한 분산 저장 시스템이라고 볼 수 있다.
어떤 형태로 저장 될까? - 다양한 종류의 데이터 모델
- Key Value DB
Key Value 의 쌍으로 데이터가 저장되는 가장 단순한 형태의 솔루션
Dynamo, Redis
- Wide Columnar Store
Key Value 에서 발전된 형태의 Column Family 데이터 모델을 사용
Cassandra, ScyllaDB
- Document DB
JSON, XML과 같은 Collection 데이터 모델 구조를 채택
MongoDB
- Graph DB
Nodes, Relationship, Key-Value 데이터 모델을 채용
Neo4J
Redis
Cache
나중에 요청할 결과를 미리 저장해 두었다가, 빠르게 서비스를 해주는 것.
Cache 전략
Look a side
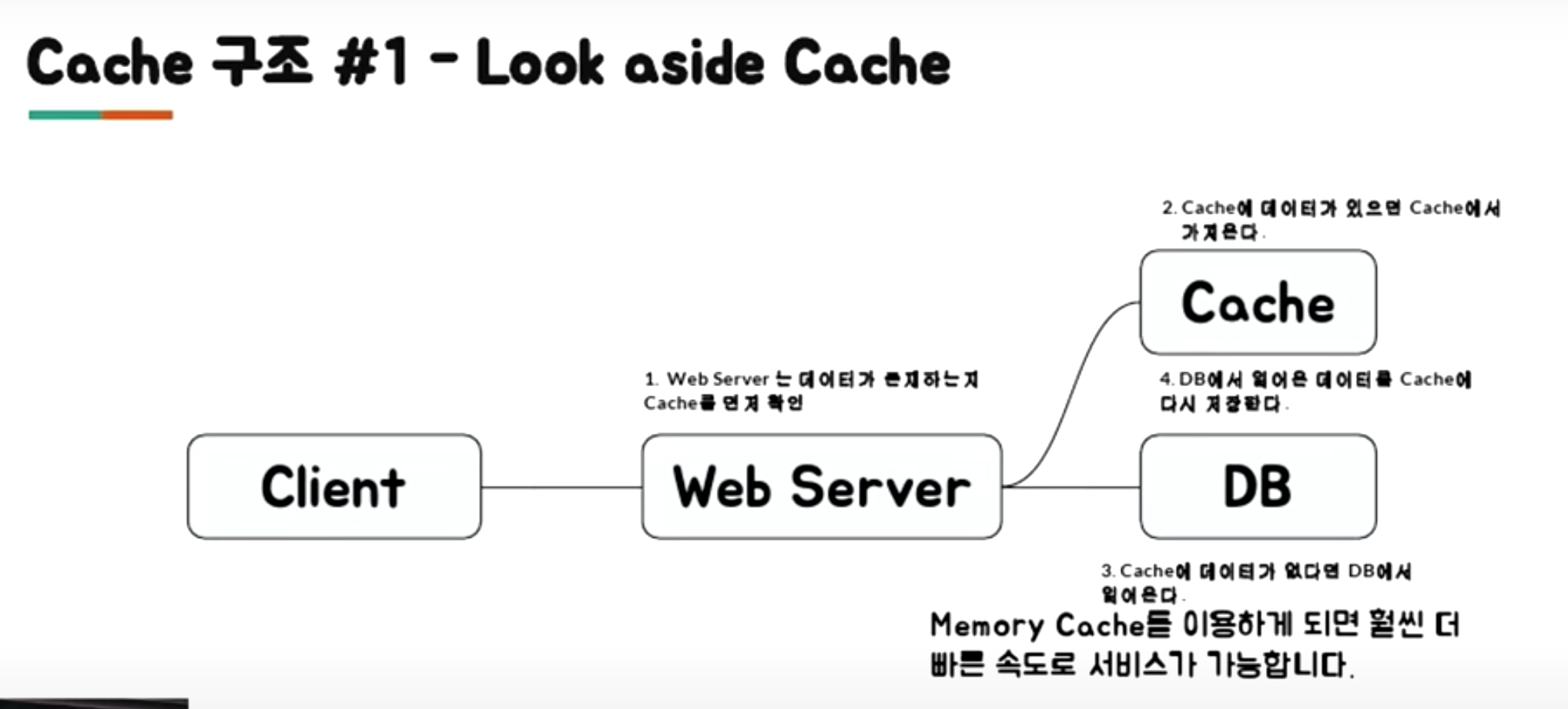
- 읽기가 많은 워크로드에 적합합니다.
-
캐시 클러스터가 다운되어도 시스템 전체의 오류로 가지 않습니다.
- 캐시에 없는 데이터인 경우, 더 오랜 시간이 걸리게 됩니다.
- 캐시가 최신 데이터를 가지고 있는가? (동기화 문제가 중요하게 됩니다.)
Write back : insert 쿼리 1개 500 번, insert 쿼리 500개 1개
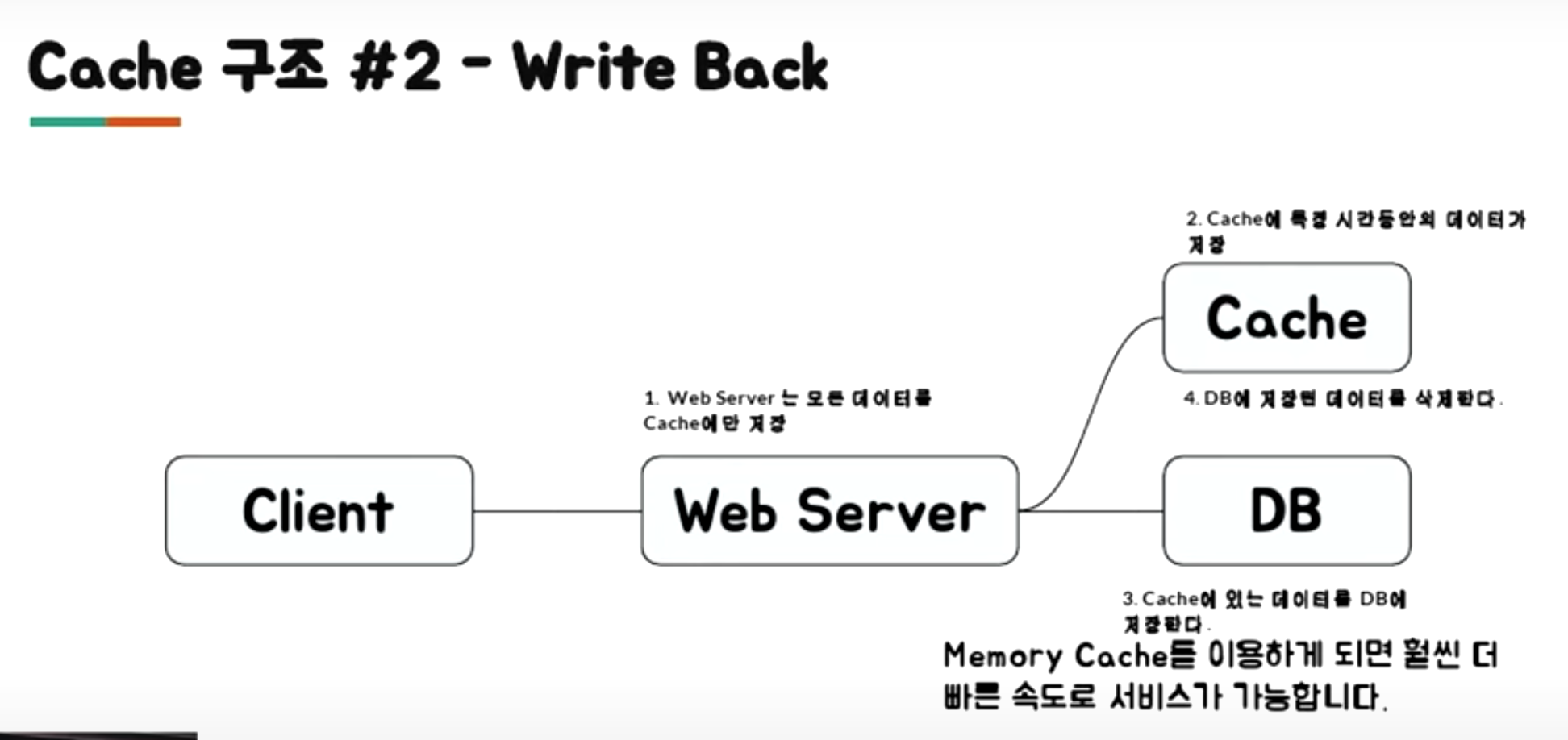
- 쓰기가 많은 워크로드에 적합합니다.
- 가장 최근에 업데이트되고 엑세스 된 데이터를 항상 캐시에서 사용할 수 있는 혼합 워크로드에 적합합니다.
-
데이터베이스에 대한 전체 쓰기를 줄일 수 있어, 해당 비용을 감소할 수 있습니다.
- 캐시에서 오류가 발생하면 데이터 영구소실.
왜 Collection 이 중요한가? :: Memarched vs Redis
- 개발의 편의성
- 개발의 난이도
- ex - 랭킹서버
- 직접 구현 해도 되지만, Redis 의 Sorted Set 을 이용하면 랭킹 구현 가능.
- 다만 가져다 쓰면 해당 기술의 한계에 종속적.
- NoSql 특성상 ACID 가 약하여 RaceCondition 에 취약 할 수 있는데
Redis 의 경우 자료구조가 Atomic 하기 때문에 RaceCondition 피할 수 있다.
개발 시간을 단축 시키고 문제를 줄여줄 수 있다.
전역객체 또는 필드로 저장해도 메모리 DB 인데 그거랑 뭐가 다를까?
- 서버가 여러대인 경우 Consistency 문제 발생
- 세션 같은 경우 A 서버에서 세션 저장 하면 -> B 서버에는 세션 객체 없기 때문에 문제 발생.
Redis 사용 처
- Remote Data Store
A, B, C 서버에서 데이터를 공유 하고 싶을때
- 인증 토큰 저장
- Ranking board 사용 (Sorted Set)
- 유저 API Limit
Redis Collections
- Strings (Key-Value) : 가장 많이씀.
보통 prefix 붙임. key 값에 token:1234567
단순 증감 연산 효율 (연산 함수 제공)
- List (LinkedList 와 유사)
Blocking 기능을 통해 이벤트 queue 구현 가능.
- Set : 데이터가 있는지 없는지만 체크하는 용도 (특정 유저 follow 목록)
- Sorted Set : 가장 많이 씀. - 랭킹에 따라 순서가 바뀌길 바란다면
- Hash
- Streams
로그를 저장하기 가장 적절한 자료구조.
:: 하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않음.
10000개 이하 몇천개 수준으로 유지하는게 좋다.
:: Expire item 개별로 걸리지 않고 전체 Collection 에 걸리기 때문에
위의 많은 개수들이 모두 삭제 되고 모두 가져오게 됨 - 성능적 부하.
Redis 운영
- 메모리 관리를 잘하자.
- Maxmemory 를 설정하더라도 이보다 더 사용할 가능성이 큼.
- 멀티쓰레드 환경에서 RaceCondition 으로 발생하는 문제 취약. - 잦은 ContextSwitching 으로 쓰레드가 경합하면서 생기는 문제들
- Redis 는 기본적으로 Single Thread
- Redis 기본 자료구조는 Atomic 하기 때문에, 서로 다른 트랜잭션의 Read/Write 동기화
- O(N) 관련 명령어는 주의하자.
- Redis 는 Single Thread 기반이기 때문에 keys, flushall, flushdb, getall 등 조심.
Replication - Fork
- 메모리 데이터 이기 때문에 유실될 때를 어떻게 대비 할 것인가? 에 대한 해결책.
- Fork 할때 메모리 여유 있게 사용.
꿀팁
- keys * -> scan 으로 대체
- hgetall -> hscan
- del -> unlink
MAXMEMORY-POLICY = ALLKEYS-LRU (메모리가 가득 찼을 때 가장 바람직한 POLICY) redis 캐시로 이용 할때 , ExpireTime 설정 권장.
Leave a comment